
Kubernetes资源控制器
内容来自尚硅谷。
Kubernetes中内建了很多controller(控制器),这些相当于一个状态机,用来控制Pod的具体状态和行为。
控制器类型:
- ReplicationController 和 ReplicaSet
- Deployment
- DaemonSet
- StateFulSet
- Job/CronJob
- Horizontal Pod Autoscaling
ReplicationController 和 ReplicaSet
ReplicationController(RC)用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的 Pod 来替代;而如果异常多出来的容器也会自动回收。
在新版本的 Kubernetes 中建议使用 ReplicaSet 来取代 ReplicationController 。ReplicaSet 跟ReplicationController 没有本质的不同,只是名字不一样,并且 ReplicaSet 支持集合式的 selector。
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80Deployment
Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义 (declarative) 方法,用来替代以前的ReplicationController 来方便的管理应用。典型的应用场景包括:
- 定义 Deployment 来创建 Pod 和 ReplicaSet
- 滚动升级和回滚应用
- 扩容和缩容
- 暂停和继续 Deployment
RS与Deployment的关系:
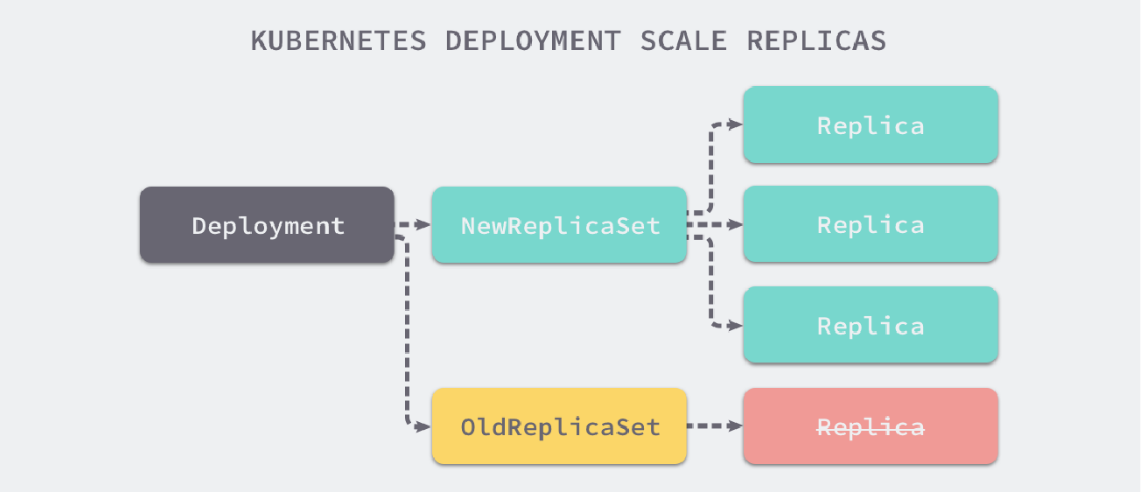
部署简单的nginx应用
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80kubectl apply -f https://kubernetes.io/docs/user-guide/nginx-deployment.yaml --record
# --record参数可以记录命令,我们可以很方便的查看每次 revision 的变化扩容
kubectl scale deployment nginx-deployment --replicas 10自动扩展
如果集群支持 horizontal pod autoscaling 的话,还可以为Deployment设置自动扩展。
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80更新镜像
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1回滚
kubectl rollout history deployment/nginx-deployment
kubectl rollout undo deployment/nginx-deployment
kubectl rollout undo deployment/nginx-deployment --to-revision=2 ## 可以使用 --revision参数指定某个历史版本
kubectl rollout pause deployment/nginx-deployment ## 暂停 deployment 的更新查看 rollout 的状态
kubectl rollout status deployment/nginx-deployment如果 rollout 成功完成, kubectl rollout status 将返回一个0值的 Exit Code。
$ kubectl rollout status deploy/nginx
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx" successfully rolled out
$ echo $?
0编辑Deployment
kubectl edit deployment/nginx-deployment查看历史RS
kubectl get rsDeployment更新策略
Deployment 可以保证在升级时只有一定数量的 Pod 是 down 的。默认的,它会确保至少有比期望的Pod数量少一个是up状态(最多一个不可用)。
Deployment 同时也可以确保只创建出超过期望数量的一定数量的 Pod。默认的,它会确保最多比期望的Pod数量多一个的 Pod 是 up 的(最多1个 surge )。
未来的 Kuberentes 版本中,将从1-1变成25%-25%。
kubectl describe deploymentsRollover(多个rollout并行)
假如您创建了一个有5个 niginx:1.7.9 replica的 Deployment,但是当还只有3个 nginx:1.7.9 的 replica 创建出来的时候您就开始更新含有5个 nginx:1.9.1 replica 的 Deployment。在这种情况下,Deployment 会立即杀掉已创建的3个 nginx:1.7.9 的 Pod,并开始创建 nginx:1.9.1 的 Pod。它不会等到所有的5个 nginx:1.7.9 的Pod 都创建完成后才开始改变航道。
清理Policy
您可以通过设置 .spec.revisonHistoryLimit 项来指定 deployment 最多保留多少 revision 历史记录。默认的会保留所有的 revision;如果将该项设置为0,Deployment 就不允许回退了。
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个Pod 。当有 Node 从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet的典型用法:
- 运行集群存储 daemon,例如在每个 Node 上运行
glusterd、ceph - 在每个 Node 上运行日志收集 daemon,例如
fluentd、logstash - 在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、
collectd、Datadog 代理、New Relic 代理,或 Gangliagmond
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
containers:
- name: daemonset-example
image: wangyanglinux/myapp:v1Job
Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
特殊说明:
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1.spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: NeverCronJob
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
使用前提条件:当前使用的 Kubernetes 集群,版本 >= 1.8(对 CronJob)。对于先前版本的集群,版本 <
1.8,启动 API Server时,通过传递选项 --runtime-config=batch/v2alpha1=true 可以开启 batch/v2alpha1
API
典型的用法如下所示:
- 在给定的时间点调度 Job 运行
- 创建周期性运行的 Job,例如:数据库备份、发送邮件
CronJob Spec
-
.spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron -
.spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job -
.spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限 -
.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
只允许指定下面策略中的一种:Allow(默认):允许并发运行 JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的 Job,用一个新的来替换
-
.spec.suspend:挂起,该字段也是可选的。如果设置为 true ,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false 。 -
.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1 。设置限制的值为 0 ,相关类型的 Job 完成后将不会被保留。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 <none>
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name})
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
# 注意,删除 cronjob 的时候不会自动删除 job,这些 job 可以用 kubectl delete job 来删除
$ kubectl delete cronjob hello
cronjob "hello" deletedCronJob本身的一些限制
创建 Job 操作应该是幂等的。
StatefulSet
StatefulSet 作为 Controller 为 Pod 提供唯一的标识。它可以保证部署和 scale 的顺序。
StatefulSet是为了解决有状态服务的问题(对应Deployments和ReplicaSets是为无状态服务而设计),其应用
场景包括:
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
Horizontal Pod Autoscaling
应用的资源使用率通常都有高峰和低谷的时候,Horizontal Pod Autoscaling可以削峰填谷,提高集群的整体资源利用率,让service中的Pod个数自动调整,使Pod水平自动缩放。
如:在CPU利用率大于或小于某值的时候调整Pod的数量。
Comments NOTHING